Technology
Sruffer DB: The Database That Actually Makes Sense for Modern Applications

Your database just crashed during peak traffic hours. Again. You’re staring at error logs, your team’s scrambling to restore services, and customers are flooding support channels. Sound familiar? Traditional databases weren’t built for what we’re asking them to do anymore—and that’s where sruffer db enters the conversation.
Here’s what nobody tells you upfront about modern database solutions: most are solving yesterday’s problems while marketing themselves as tomorrow’s answers. Sruffer db takes a different approach by focusing on what developers actually need right now—real-time analytics, flexible scaling, and architecture that doesn’t require a PhD to implement. Whether that translates to value for your specific situation? That’s what we’ll figure out together.
What Sruffer DB Actually Is (Beyond the Marketing)
Sruffer db is a database management system built specifically for applications that need to process large amounts of data quickly without the rigid structure traditional databases impose. Think of it as the difference between a filing cabinet and a modern search engine—both store information, but one adapts to how you actually work.
The core innovation lies in its architecture. Traditional databases use predefined schemas—you decide your data structure upfront, and changing it later feels like renovating a house while people still live in it. Sruffer db uses flexible schemas that adapt as your needs evolve. Your e-commerce store suddenly needs to track 15 new customer attributes? Update your data model without taking everything offline.
Real-time analytics sets sruffer db apart from databases that require batch processing. Instead of waiting hours for reports, you get insights as data flows in. For businesses making decisions based on current conditions—pricing algorithms, inventory management, fraud detection—this timing difference matters enormously.
The distributed design means your database doesn’t live on one overwhelmed server. Data spreads across multiple nodes, so when traffic spikes, performance doesn’t crater. I’ve watched companies struggle through holiday shopping seasons because their database couldn’t handle the load. Sruffer db addresses this by design rather than requiring expensive emergency scaling.
Why Traditional Databases Struggle With Modern Demands
Traditional relational databases emerged in the 1970s when data looked very different. Structured tables worked brilliantly for banking records, inventory systems, and payroll. They’re still excellent for those use cases. But modern applications generate semi-structured or unstructured data—user interactions, sensor readings, social media content, logs—that doesn’t fit neatly into rows and columns.
Scaling traditional databases vertically means buying bigger servers. Eventually you hit hardware limits or budget constraints. Horizontal scaling—spreading data across multiple servers—is possible but complex and often bolted on rather than built in. Sruffer db was designed from scratch for horizontal scaling, making it inherently more flexible.
Performance becomes another pain point. Traditional databases excel at complex queries across structured data. When you’re analyzing relationships—which customers bought which products when—they’re great. For simple, rapid data retrieval at massive scale, they’re overkill. Sruffer db optimizes for the high-speed, high-volume scenarios modern applications demand.
The maintenance burden adds up too. Traditional systems require database administrators to tune performance, manage backups, handle failover scenarios, and coordinate updates. Sruffer db automates many of these tasks, reducing the specialized expertise required to keep things running smoothly.
Key Features That Actually Matter
Adaptive Scaling — Most databases make you choose capacity upfront. Too little and you crash under load. Too much and you’re paying for unused resources. Sruffer db adjusts automatically as demand fluctuates. Your application goes viral overnight? The database handles it without manual intervention or emergency budget meetings.
Real-Time Processing — Traditional analytics work like this: collect data all day, process it overnight, review reports the next morning. By then, the moment’s passed. Sruffer db processes data as it arrives, enabling split-second decisions based on current conditions rather than yesterday’s snapshot.
Flexible Data Models — Starting a project, you don’t always know every field you’ll eventually need. Traditional databases punish this uncertainty with painful migrations. Sruffer db treats schema flexibility as a feature, not a workaround. Add fields, change structures, evolve your data model without the drama.
Built-In Security — Rather than bolting security onto an older architecture, sruffer db incorporates encryption and access controls from the ground up. Data stays protected whether it’s stored, processed, or transmitted between nodes.
Cloud-Native Design — Whether you’re running on AWS, Azure, Google Cloud, or hybrid infrastructure, sruffer db integrates naturally with cloud services. This isn’t a legacy system awkwardly ported to the cloud—it’s designed for how modern applications actually deploy.
Where Sruffer DB Makes the Most Sense
E-commerce platforms benefit significantly because they need real-time inventory updates, personalized recommendations based on current browsing, and the ability to handle traffic spikes during sales or product launches. One retailer I know reduced cart abandonment by 18% after implementing real-time stock updates—customers weren’t ordering items that sold out during checkout anymore.
IoT applications generate massive data streams from sensors, devices, and monitoring systems. Traditional databases drown in this volume. Sruffer db handles high-velocity data ingestion while enabling real-time monitoring and alert systems. Manufacturing facilities use this for predictive maintenance—catching equipment issues before they cause downtime.
Financial services applications need both speed and security for fraud detection, algorithmic trading, and risk analysis. Sruffer db’s real-time processing catches suspicious transactions in milliseconds rather than hours, preventing fraud before it completes.
Healthcare platforms managing patient records, appointment scheduling, and real-time monitoring benefit from flexible data models—medical information varies widely between patients and changes as treatment progresses. Sruffer db accommodates this variability while maintaining security compliance.
Social platforms and content networks dealing with user-generated content, interactions, and recommendations need databases that scale horizontally and process relationships efficiently. Sruffer db handles the graph-like nature of social connections more gracefully than traditional relational approaches.
The Honest Limitations You Should Know
Sruffer db isn’t mature software with decades of production battle-testing. Traditional databases like PostgreSQL or MySQL have encountered and solved countless edge cases. You’re less likely to hit undocumented bugs or surprising limitations with established systems. With sruffer db, you’re trading maturity for modern features.
The learning curve exists, especially for teams deeply familiar with SQL and relational concepts. While sruffer db simplifies some aspects, it introduces new patterns and approaches. Budget time for your team to build competence—this isn’t a drop-in replacement you implement Friday afternoon.
Community support and resources pale compared to established databases. Stack Overflow has millions of MySQL questions and answers. Sruffer db? A fraction of that. Finding solutions to specific problems takes more detective work. Documentation exists but doesn’t have the depth decades of community contributions provide.
Integration complexity can surprise you. Most tools, frameworks, and third-party services expect traditional databases. Want to connect your favorite business intelligence tool? You might need custom connectors or workarounds that wouldn’t be necessary with PostgreSQL.
For simple applications with straightforward data and modest scale, sruffer db is probably overkill. If you’re building a blog, small business website, or internal tool with predictable usage patterns, traditional options work fine and cost less in both money and complexity.
Making the Switch: What Actually Matters
Don’t migrate your entire system at once. Start with a new feature or non-critical component. Learn how sruffer db behaves in production without risking your core business. One company I worked with rolled it out for their recommendation engine first—important but not catastrophic if it struggled initially.
Evaluate your data patterns honestly. High-volume writes, real-time requirements, and flexible schemas favor sruffer db. Complex transactions, heavy joins, and structured reporting favor traditional databases. Some applications need both—use the right tool for each component rather than forcing everything into one system.
Consider your team’s skill set. A team comfortable with NoSQL concepts and distributed systems will adapt faster than one steeped in decades of SQL expertise. Training costs money and time. Factor this into ROI calculations alongside licensing and infrastructure.
Cloud costs deserve scrutiny. Sruffer db’s scaling flexibility can reduce costs during quiet periods, but misconfigured systems can rack up bills during peak usage. Set up cost monitoring and alerts before going to production. Test your assumptions about typical and peak loads with realistic data.
Start with managed services if available. Running your own sruffer db cluster adds operational complexity. Managed options handle updates, backups, monitoring, and failover—letting your team focus on application logic rather than database operations. The premium often proves worthwhile.
Real-World Performance Expectations
Speed improvements vary wildly depending on your specific use case. For simple key-value lookups at scale, sruffer db can be 5-10x faster than traditional databases. For complex analytical queries, traditional systems might actually perform better. Benchmark your actual queries, not generic performance claims.
Scaling behavior changes your cost structure. Traditional databases follow predictable, linear costs—bigger server, higher price. Sruffer db’s distributed nature means costs scale with usage more granularly. This benefits variable workloads but complicates budget forecasting.
Maintenance time typically decreases, but differently than expected. Less time tuning queries and managing schema changes, more time monitoring distributed system health and optimizing data distribution patterns. The work changes more than it disappears.
What You Need to Remember About Sruffer DB
Sruffer db solves specific modern database challenges—real-time analytics, flexible schemas, horizontal scaling—that traditional databases struggle with. It’s not universally better, just better for certain scenarios. If your application needs instant insights from high-volume data, flexible data structures, or automatic scaling, sruffer db deserves serious evaluation.
The trade-offs are real. Less maturity, smaller community, learning curve, and integration challenges come with those modern features. Factor these honestly into your decision rather than chasing trendy technology for its own sake.
Start small, measure results, and expand gradually. Database decisions are among the hardest to reverse in application architecture. Prove sruffer db works for your specific needs with limited risk before betting your entire infrastructure on it. The technology is promising, but only you can determine if it’s promising for your actual situation and challenges.

-
 Blog5 months ago
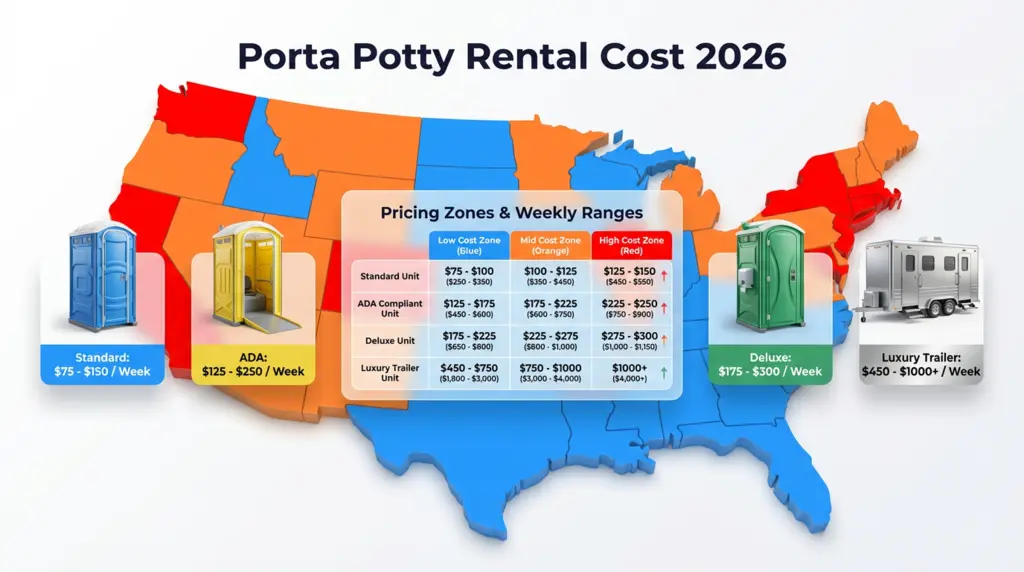
Blog5 months agoHow Much Does It Cost to Rent a Porta Potty? (2026 Pricing Guide)
-
Lifestyle7 months ago
The Ultimate Guide to Choosing Contact Lenses for Beginners
-
Lifestyle6 months ago
Babydollkaila: The Alt-Fashion Icon Redefining Digital Style
-
Uncategorized6 months ago
Healthy Habits for Supporting Women’s Hair Wellness
-
News8 months ago
Is Debby Clarke Belichick Still Alive? 2025 Update & Truth
-
Blog5 months ago
Common Questions About Workplace Rights
-
Technology7 months ago
6 Free AI Tools to Create AI Videos Right Now
-
News7 months ago
Melissa Sinkevics: The Woman Behind the Pageant Crown